Svenska litteratursällskapet i Finland > Digitala utgåvor & databaser
Svenska litteratursällskapet i Finland > Digitala utgåvor & databaser

En digital utgåva av Tove Janssons arkivmaterial och litterära verk kommer att lanseras i juni 2026.
I den utgåvan kan forskare och andra intresserade följa författarens kreativa process och jämföra olika versioner av manuskript och tidiga upplagor av tryckta böcker.
Foto: Fred Ohert. Hufvudstadsbladet, Journalistiska bildarkivet JOKA, Museiverket

I den digitala utgåvan Brev, artiklar och fältstudier publiceras Edvard Westermarcks tidnings- och tidskriftsartiklar, en omfattande del av hans korrespondens samt de självbiografiska böckerna Sex år i Marocko och Minnen ur mitt liv.
Utgåvan belyser Westermarcks roll som forskare och offentlig intellektuell och öppnar nya perspektiv på en central gestalt i Finlands vetenskaps- och idéhistoria.

I vår prisbelönta textkritiska utgåva Zacharias Topelius Skrifter presenteras Topelius mångsidiga och långa författarskap. I utgåvan på 23 delar ingår lyrik, epik, barnlitteratur och dramatik, historia och geografi, publicistik och religiösa skrifter, brev och dagböcker.
Foto: Historiska bildsamlingen/Museiverket

I den digitala utgåvan finns Albert Edelfelts 1 310 brev till modern Alexandra Edelfelt, skrivna åren 1867–1901. Breven är transkriberade med hjälp av AI-programmet Transkribus. De är sökbara genom fulltext, ämnesord, personer och platser. Utgåvan är ett samarbete med Finlands Nationalgalleri och innehåller en stor samling digitaliserade bilder av konstverk och skisser. De har kopplats till de brev där Edelfelt skriver om sina verk.

Den finländska socialantropologen Hilma Granqvist gjorde sitt livsarbete och sin viktigaste forskning i den palestinska byn Artas 1925–1931. I Hilma Granqvists arkiv finns fotografier, korrespondens med kolleger och vänner, fältanteckningar, resedagböcker, fem publicerade böcker och två opublicerade bokmanuskript.
Foto: Palestine Exploration Fund, London, Storbritannien

Den okände von Wright ger nya vinklar på en av 1900-talets mest lyskraftiga filosofer, Georg Henrik von Wright. Här finns texter från sju årtionden: bland annat von Wrights återupptäckta tidskritik, hans brevväxling med Eino Kaila och essäer om Ludwig Wittgenstein.
Foto: Knut Erik Tranøy

Kerstin Söderholm var en uppskattad lyriker och litteraturkritiker. Hon hörde till den finlandssvenska modernistgenerationen och blev känd för sina självutlämnande dagböcker, som utgavs postumt 1947–1948. På soderholm.sls.fi finns Söderholms dagböcker, brev och skönlitterära manuskript.

Tjugotalsmodernisten Henry Parland har gått till historien som en banbrytande poet, en intellektuell kritiker och en semiotisk pionjär. På parland.sls.fi samlas Parlands texter i fyra delar: Dikter, Prosa, Kritik, Korrespondens och hans enda roman, Sönder.

Finlands svenska folkdiktning är en skattkista full av äldre finlandssvensk folktradition insamlad i slutet av 1800-talet och under 1900-talets första decennier. Här hittar du över 12 000 sidor med sagor, sägner, ordstäv, gåtor, folkmusik, folktro och lekar. Här hittar du också musikvolymerna i bearbetat format – över 3000 melodier att lyssna på och ladda ner, samt mycket information om spelmän, upptecknare och den finlandssvenska spelmanstraditionen.

Fodermarsk, tuberkulosdispensärbyrå, apostolinen vikaari … Vare sig du är forskare, översättare eller intresserad av släktforskning kan Förvaltningshistorisk ordbok vara till hjälp. Ord, termer och uttryck är indelade i temahelheter och kronologiska perioder, från medeltiden fram till 1950.

Biografiskt lexikon för Finland (BLF) är ett uppslagsverk om personer med anknytning till Finland, från korstågstiden fram till 2010-talet. Verket omfattar mer än 1 600 artiklar om allt från kungar och presidenter till författare, hantverkare och programmerare.

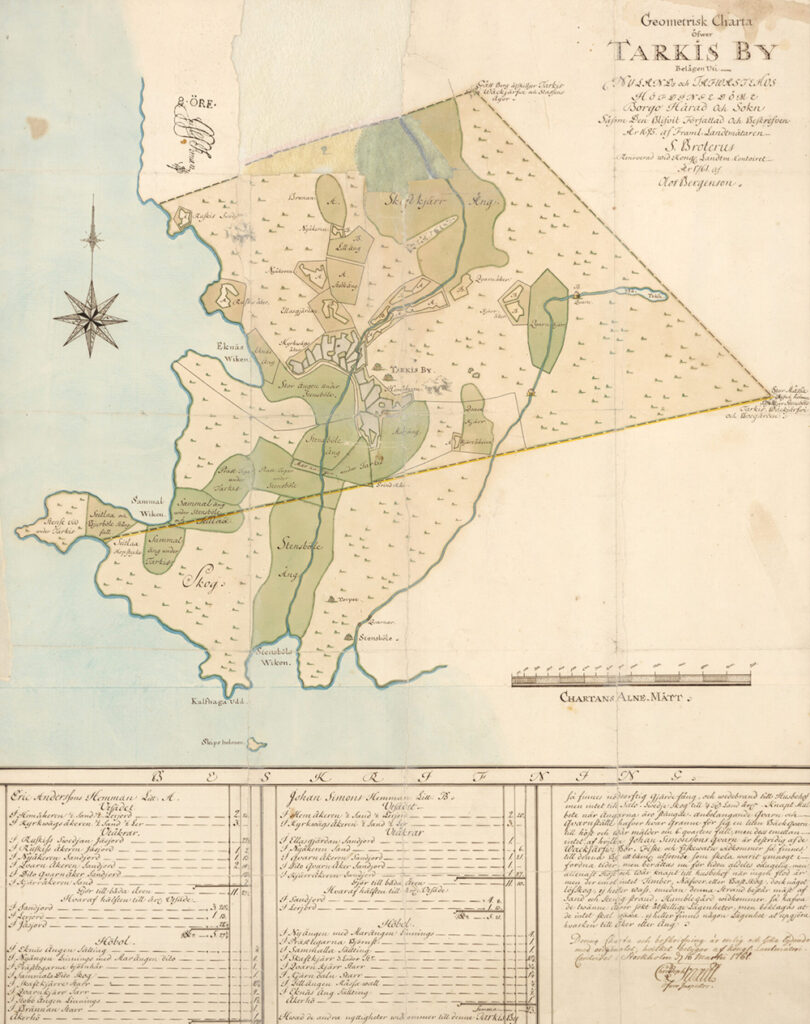
Vill du pröva på recept med citron, bondbönor eller kanske krusmynta? Historiska recept samlar in och bevarar matkultur från förr och här kan du söka bland över tusen 1700- och 1800-talsrecept enligt ämnesord. Handskrifter från Villnäs, Åbotrakten, Nagu, Stensböle, Ackas och Hertonäs gård har publicerats och flera läggs ut vartefter.
Foto: Katja Hagelstam

1918 – Jag var där är ett tvåspråkigt läromedel som bygger på unikt arkivmaterial som belyser hur inbördeskriget påverkade den enskilda människan och hela samhället.
Boken är ett samarbete mellan Svenska litteratursällskapet i Finland och Suomalaisen Kirjallisuuden Seura. Förutom arkivmaterial ingår källkritisk vägledning och uppgifter.
Webbplatsen 1918 består av två helheter, som stöder varandra:

Zacharias Topelius läsebok för folkskolan Boken om Vårt Land (1875) och den finska översättningen Maamme kirja (1876) har format bilden av Finlands historia, folk och kultur i generationer. Den digitala utgåvan Maamme kirja har getts ut i samarbete med Finska Litteratursällskapet (SKS).

Talko är en talspråkskorpus som innehåller inspelningar och tillhörande sökbara utskrifter. Utskrifterna har försetts med ordklasstaggar och en del morfologisk information, vilket ger mångsidiga sökmöjligheter i materialet. Talko innehåller huvudsakligen inspelningar gjorda 2005–2008 inom projektet Spara det finlandssvenska talet, men även en liten andel äldre arkivinspelningar ingår. Användare med en e-postadress från ett universitet kan logga in direkt via CLARIN-inloggning, övriga användare kan ansöka om ett eget CLARIN-användarkonto.

Lyssna på ljudprov ur intervjuer med både yngre och äldre talare från olika orter i Svenskfinland. Du kan lyssna både på inspelningar som gjordes 2005–2008 inom projektet Spara det finlandssvenska talet (Spara talet) och på några ljudprov ur äldre samlingar i SLS arkiv. Materialet finns på söktjänsten Finna.

Här finns 19 000 finlandssvenska ordspråk och talesätt på dialekt samlade. Du kan söka på ämnesord eller ort, eller i en kategori. Bland de drygt 40 tematiska kategorierna finns till exempel ”Tala och tiga”, ”Djuren i ordstäven” och ”Laster, dygder, ärlighet och falskhet”.
Illustration: Bosse Österberg

Här kan du läsa om inofficiella namn på platser i städerna Karleby, Lovisa, Vasa, Åbo, Mariehamn, Ekenäs, Helsingfors, Borgå, Karis och Jakobstad. Webbplatsen kan med fördel även användas som utgångspunkt för diskussion och arbeten i undervisningen. På webbplatsen hittar du färdiga uppgifter som högstadie- och gymnasieelever kan arbeta med.
Webbutgåvan upptar samtliga bynamn, kommun- och stadsnamn, historiska sockennamn och namn på landskap i svenskspråkiga och tvåspråkiga trakter samt ett urval svenska namn i finskspråkiga trakter. Sammanlagt ingår närmare 3 000 ortnamn. För varje bebyggelsenamn ges en beskrivning med namnets etymologi, beskrivningar av de namnelement som ingår i ordet och äldre namnformer. Dessutom är databasen kopplad till en kartfunktion som visar var orten är belägen.

Sägenkartan är en digital plattform med tusentals berättelser om väsen och föreställningar i folktron i det svenska Finland, Sverige, Norge och Estland. Sägnerna är sökbara och kopplade till den ort där de samlats in. Sägenkartan är producerad i samarbete med Institutet för språk och folkminnen samt Norsk Folkminnesamling (Universitetet i Oslo).

Daniel är en databas som i första hand innehåller dramatik skriven på svenska av författare i Finland. I princip omfattar den alla slag av scentexter och arrangemang för scenen. Kronologiskt löper databasen från 1819 fram till senaste kalenderår.

Databasen innehåller cirka 2 500 av Jarl Pousars volymer från olika länder och sekler: vetenskaplig litteratur, bland annat teologi och humaniora, reseskildringar, skönlitteratur, barnböcker, psalmböcker och kartverk. I databasen ingår också bilder på samtliga bokband, titelblad, mönstrade försättspapper, bevarade originalomslag och frontespiser.

Databasen Herrgårdar är en översiktskatalog som för forskningsändamål ger uppgifter om historiska arkiv och bibliotek på herrgårdar i Finland. Databasen är ett hjälpmedel för forskare inom bland annat historia och kulturhistoria, och kan också vara till nytta för till exempel släktforskare.